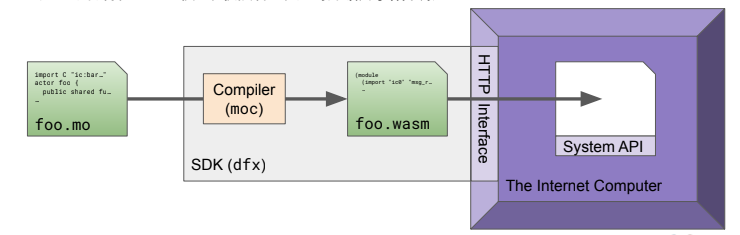
CICD是什么? 由于目前公司使用的gitlab,大部分项目使用的CICD是gitlab的CICD,少部分用的是jenkins,使用了gitlab-ci一段时间后感觉还不错,因此总结一下
介绍gitlab的CICD之前,可以先了解CICD是什么
我们的开发模式经历了如下的转变:瀑布模型->敏捷开发→DevOps(Development、Operations的组合词,是一组过程、方法与系统的统称)
后来随着DevOps的兴起,出现了持续集成(Continuous Integration)、持续交付(Continuous Delivery) 、持续部署(Continuous Deployment) 的新方法,关于持续集成、持续交付、持续部署,总结如下:
持续集成 的重点是将各个开发人员的工作集合到一个代码仓库中。通常,每天都要进行几次,主要目的是尽早发现集成错误,使团队更加紧密结合,更好地协作。持续交付 的目的是最小化部署或释放过程中固有的摩擦。它的实现通常能够将构建部署的每个步骤自动化,以便任何时刻能够安全地完成代码发布(理想情况下)。持续部署 是一种更高程度的自动化,无论何时对代码进行重大更改,都会自动进行构建/部署。
持续集成的好处是什么? 持续集成可以使问题尽早暴露,从而也降低了解决问题的难度,正如老马所说,持续集成无法消除bug,但却能大大降低修复的难度和时间。
持续交付的好处是什么? 持续交付的好处在于快速获取用户反馈;适应市场变化和商业策略的变化。开发团队保证每次提交的修改都是可上线的修改,那么决定何时上线,上线哪部分功能则完全由产品业务团队决定。
虽然持续交付有显著的优点,但也有不成立的时候,比如对于嵌入式系统的开发,往往需要软硬件的配合。
持续部署的好处是什么? 持续部署的目标是通过减少批量工作的大小,并加快团队工作的节奏,帮助开发团队在其开发流程中消除浪费。这使团队能够一直处于一种可持续的平稳流状态, 让团队更容易去创新、试验,并达到可持续的生产率
市面上的CI有很多,如果在github上搜一下ci工具,也会搜到很多,比如:
Travis CI
Circle CI
Jenkins
AppVeyor
CodeShip
Drone
Semaphore CI
Buildkite
Wercker
TeamCity
这里只介绍Gitlab-CI
Gitlab-CI
GitLab 是 CI/CD 领域的一个新手玩家,但它已经在 Forrester Wave 持续集成工具中占据了领先地位。在这样一个竞争对手众多而水平又很高的领域,这是一项巨大的成就。是什么让 GitLab CI 如此了不起?
它使用 YAML 文件来描述整个管道。
它还有一个功能叫 Auto DevOps,使比较简单的项目可以自动构建内置了若干测试的管道。
使用 Herokuish 构建包来确定语言以及如何构建应用程序。有些语言还可以管理数据库,对于构建新的应用程序并在开发过程一开始就将其部署到生产环境中,这是一个很重要的功能。
提供到 Kubernetes 集群的原生集成,并使用多种部署方法的一种(如基于百分比的部署和蓝绿部署)将应用程序自动部署到 Kubernetes 集群中。
除了 CI 功能之外,GitLab 还提供了许多补充功能,比如自动把 Prometheus 和你的应用程序一起部署,实现运行监控;使用 GitLab 问题(Issues)、史诗(Epics)和里程碑(Milestones)进行项目组合和项目管理;管道内置了安全检查,提供跨多个项目的聚合结果;使用 WebIDE 在 GitLab 中编辑代码的能力,它甚至可以提供预览或执行管道的一部分,以获得更快的反馈。
相关概念 pipeline(管道、流水线)
一次 Pipeline 其实相当于一次构建任务,里面可以包含多个流程(Stage),比如自动构建、自动进行单元测试、自动进行代码检查等流程 ;
任何提交或者 Merge Request 的合并都可以触发 Pipeline ;
Stage(构建阶段)
Stage表示构建阶段,就是上面提到的流程 ;
可以在一次 Pipeline 中定义多个 Stage;
Stage有如下特点 :
所有 stages 会按照顺序运行,即当一个 stage 完成后,下一个 Stage才会开始
只有当所有 Stage 成功完成后,该构建任务 Pipeline 才算成功
如果任何一个 Stage失败,那么后面的 Stage 不会执行,该构建任务 (Pipeline) 失败
阶段是对批量的作业的一个逻辑上的划分,每个 pipeline 都必须包含至少一个 Stage。多个 Stage是按照顺序执行的,如果其中任何一个 Stage失败,则后续的 Stage不会被执行,整个 CI 过程被认为失败。
Jobs(任务)
job表示构建工作,表示某个stage里面执行的工作 ;
一个stage里面可以定义多个job ;
jobs有如下特点 :
相同 stage 中的jobs 会并行执行
相同 stage 中的 jobs 都执行成功时,该 stage 才会成功
如果任何一个job 失败,那么该 stage 失败,即该构建任务 (Pipeline) 失败
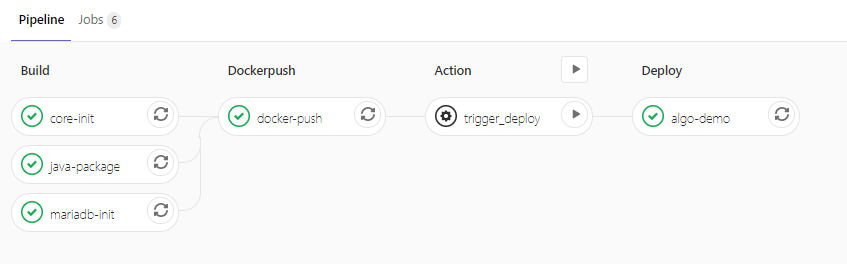
举一个例子,比如下面这个图:
这里的四个Statge(阶段): Verify、Build、Dockerpush、Deploy四个,这四个阶段组成一条Pipeline
每个阶段都有一个job,所以总共四个job,也就是unit-test、java-package、docker-push、service-1这四个,当然,每个stage可以由多个job组成,比如下面这个图:
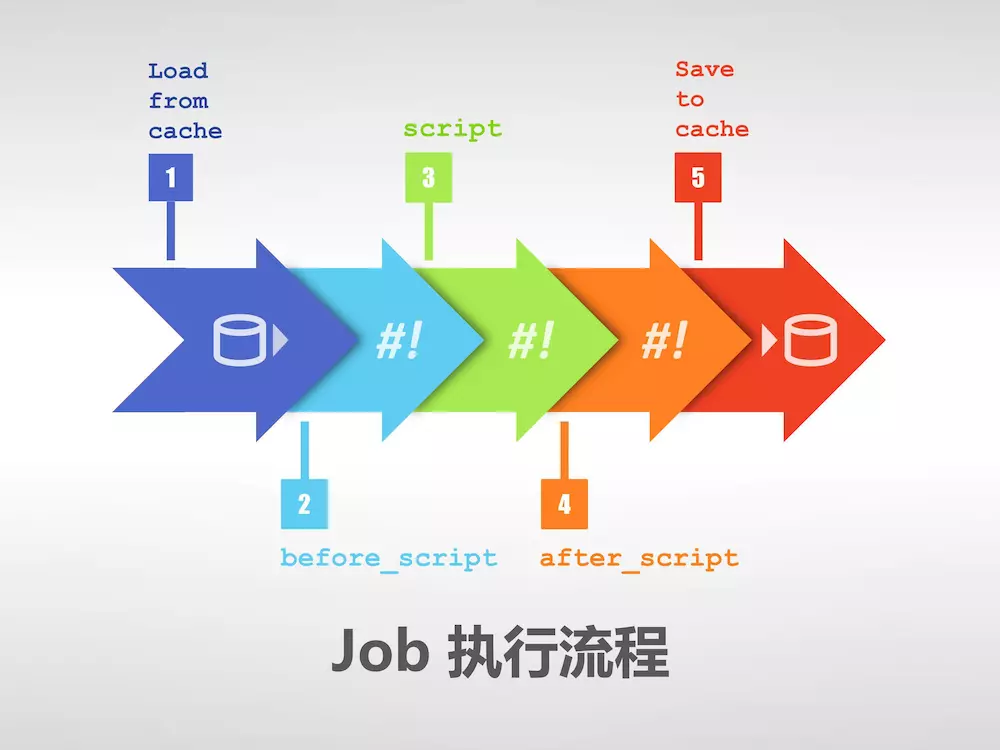
Job 的执行过程中往往会产生一些数据,默认情况下 GitLab Runner 会保存 Job 生成的这些数据,然后在下一个 Job 执行之前(甚至不局限于当次 CI/CD)将这些数据恢复。这样即便是不同的 Job 运行在不同的 Runner 上,它也能看到彼此生成的数据。
.gitlab-ci.yml中提供了 before_script 和 after_script 两个全局配置项。这两个配置项在所有 Job 的 script 执行前和执行后调用。
关于.gitlab-ci.yml、before_script、after_script是什么,先别急,在后面有介绍
在了解了 Job 配置的 script、before_script、after_script 和 cache 以后,可以将整个 Job 的执行流程用一张图概括:
所以了解了Pipeline、Stage、Jobs后,还有一个很重要的东西,就是Runner
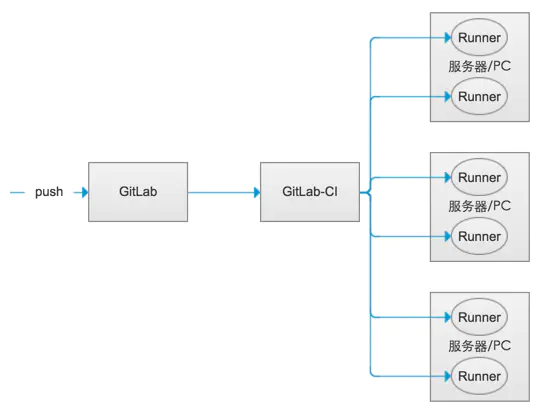
Runner Runner就像一个个的工人,而Gitlab-CI就是这些工人的一个管理中心,所有工人都要在Gitlab-CI里面登记注册,并且表明自己是为哪个工程服务的。当相应的工程发生变化时,Gitlab-CI就会通知相应的工人执行软件集成脚本。如下图所示:
gitlab里面的runner叫Gitlab-Runner,Gitlab-Runner是配合Gitlab-CI进行使用的。一般地,Gitlab里面的每一个工程都会定义一个属于这个工程的软件集成脚本,用来自动化地完成一些软件集成工作。当这个工程的仓库代码发生变动时,比如有人push了代码,GitLab就会将这个变动通知Gitlab-CI。这时Gitlab-CI会找出与这个工程相关联的Runner,并通知这些Runner把代码更新到本地并执行预定义好的执行脚本(也就是在Job执行流程那个图中所示的第三步:script),所以,Gitlab-Runner就是一个用来执行软件集成脚本script的东西。
Runner类型
Gitlab-Runner可以分类两种类型:Shared Runner(共享型) 和Specific Runner(指定型) 。
Shared Runner: 这种Runner(工人)是所有工程都能够用的。只有系统管理员能够创建Shared Runner。Specific Runner: 这种Runner(工人)只能为指定的工程服务。拥有该工程访问权限的人都能够为该工程创建Shared Runner。
关于Gitlab-runner的安装,见这篇文章:Gitlab Runner的安装配置
注册runner会对应一个tag,记住这个tag;
.gitlab-ci.yml简介 .gitlab-ci.yml 文件被用来管理项目的 runner 任务,Gitlab CI通过.gitlab-ci.yml文件管理配置job,该文件定义了statge顺序、job应该如何触发和工作、执行什么脚本、如何构建pipeline等流程
该文件存放于仓库的根目录, 默认名为.gitlab-ci.yml
我们先看一个简单的例子:.gitlab-ci.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 stages: - verify - build - dockerpush - deploy unit-test: stage: verify tags: - test-cicd script: - echo unit-test java-package: stage: build tags: - test-cicd script: - echo build docker-push: stage: dockerpush tags: - test-cicd script: - echo docker-push service-1: stage: deploy tags: - test-cicd script: - echo deploy
该配置对应下面的pipeline,test-cicd是一个Specific Runner,执行脚本的类型是shell
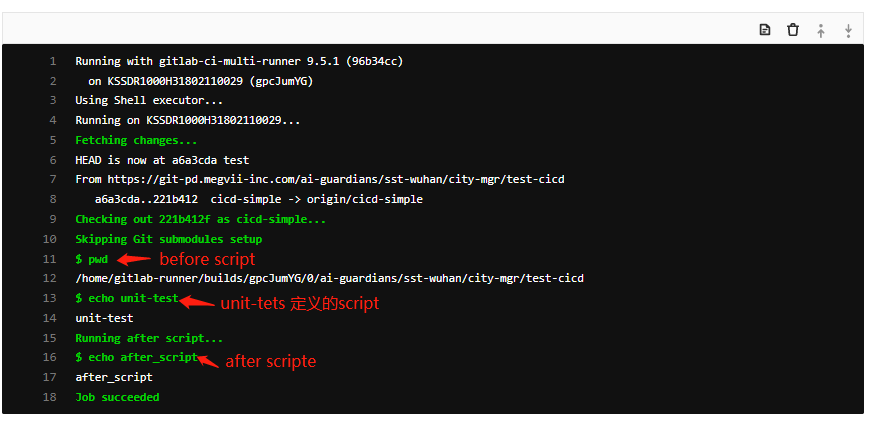
所以,以unit-test这个job为例,点击该任务可以进入到log界面查看整个log执行流程
剩下的job的执行日志都大部分如此,就不一一列举了
几个重要的关键字解析 关于gitlab-ci.yml,里面有很多关键字配置,下面我主要列举一些比较常用的关键字
before_script和after_script 随着项目越来越大,Job 越来越多,Job 中包含的重复逻辑可能会让配置文件臃肿不堪。.gitlab-ci.yml 中提供了 before_script 和 after_script 两个全局配置项。这两个配置项在所有 Job 的 script 执行前和执行后调用。
before_script 和 script 在一个上下文中是串行执行的,after_script 是独立执行的。所以根据执行器(在runner注册的时候,可以选择执行器,docker,shell 等)的不同,工作树之外的变化可能不可见,例如,在before_script中执行软件的安装。
你可以在任务中定义 before_script,after_script,也可以将其定义为顶级元素,定义为顶级元素将为每一个任务都执行相应阶段的脚本或命令。
stages stages的允许定义多个,灵活的场景阶段的pipline。定义的元素的顺序决定了任务执行的顺序。例如:
1 2 3 4 5 6 stages: - verify - build - dockerpush - deploy
build场景的任务将被并行执行。test、deploy 同理
build 任务成功后,test 执行。test 成功后,deploy 执行
所有的都成功了,提交将会标记为成功
任何一步任务失败了,提交标记为失败并之后的场景,任务都不回执行。
tags可以从允许运行此项目的所有Runners中选择特定的Runners来执行jobs。
在注册Runner的过程中,我们可以设置Runner的标签,tags可通过tags来指定特殊的Runners来运行jobs:
1 2 3 4 5 #单元测试 unit-test: stage: verify # 属于哪个流程 tags: - test-cicd # 在哪个runner上面执行,在注册runner可以自定义
script script是一段由Runner执行的shell脚本,可以执行多个,例如:
1 2 job: script: mvn clean test
这个参数也可以使用数组包含好几条命令
1 2 3 4 job: script: - pwd - mvn clean test
only and except only和except两个参数说明了job什么时候将会被创建:
only定义了job需要执行的所在分支或者标签
except定义了job不会执行的所在分支或者标签
以下是这两个参数的几条用法规则:
only和except如果都存在在一个job声明中,则所需引用将会被only和except所定义的分支过滤.
only和except允许使用正则
only和except可同时使用。如果only和except在一个job配置中同时存在,则以only为准,跳过except(从下面示例中得出)。only和except允许使用特殊的关键字:branches,tags和triggers。only和except允许使用指定仓库地址但不是forks的仓库(查看示例3)。
例子解析:
1.job将会只在issue-开头的refs下执行,反之则其他所有分支被跳过:
1 2 3 4 5 6 7 job: only: - /^issue-.*$/ except: - branches
2.job只会在打了tag的分支,或者被api所触发,或者每日构建任务上运行
1 2 3 4 5 6 job: only: - tags - triggers - schedules
3.job将会在父仓库gitlab-org/gitlab-ce的非master分支有提交时运行。
1 2 3 4 5 job: only: - branches@gitlab-org/gitlab-ce except: - master@gitlab-org/gitlab-ce
when when可以设置以下值:
on_success - 只有前面stages的所有工作成功时才执行。 这是默认值。
on_failure - 当前面stages中任意一个jobs失败后执行。
always - 无论前面stages中jobs状态如何都执行。
manual - 手动执行(GitLab8.10增加)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 stages: - build - cleanup_build - test - deploy - cleanup build_job: stage: build script: - make build cleanup_build_job: stage: cleanup_build script: - cleanup build when failed when: on_failure test_job: stage: test script: - make test deploy_job: stage: deploy script: - make deploy when: manual cleanup_job: stage: cleanup script: - cleanup after jobs when: always
脚本说明:
只有当build_job失败的时候才会执行`cleanup_build_job 。
不管前一个job执行失败还是成功都会执行`cleanup_job 。
可以从GitLab界面中手动执行deploy_jobs。
manual:
在GitLab的用户界面中显示该作业的“播放”按钮
意味着deploy_job仅在单击“播放”按钮时才会触发job。
修改上面那个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 stages: - verify - build - dockerpush - deploy - cleanup before_script: - pwd after_script: - echo after_script unit-test: stage: verify tags: - test-cicd script: - echo unit-test java-package: stage: build tags: - test-cicd script: - echo build docker-push: stage: dockerpush tags: - test-cicd script: - echo docker-push service-1: stage: deploy tags: - test-cicd script: - echo deploy when: manual cleanup_job: stage: cleanup script: - echo clean up when: always
pipeline如下:
allow_failure 跟when一起控制job执行与否的配置还有一个就是allow_failure
allow_failure可以用于当你想设置一个job失败的之后并不影响后续的CI组件的时候。失败的jobs不会影响到commit状态。
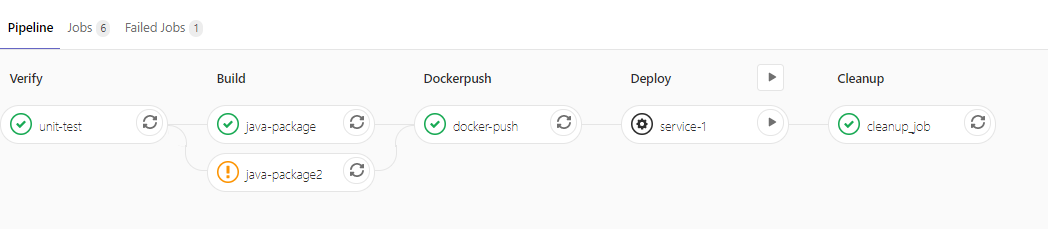
下面的这个例子中,java-package和java-package2将会并列进行,如果java-package2失败了,它也不会影响进行中的下一个stage,因为这里有设置了allow_failure: true。
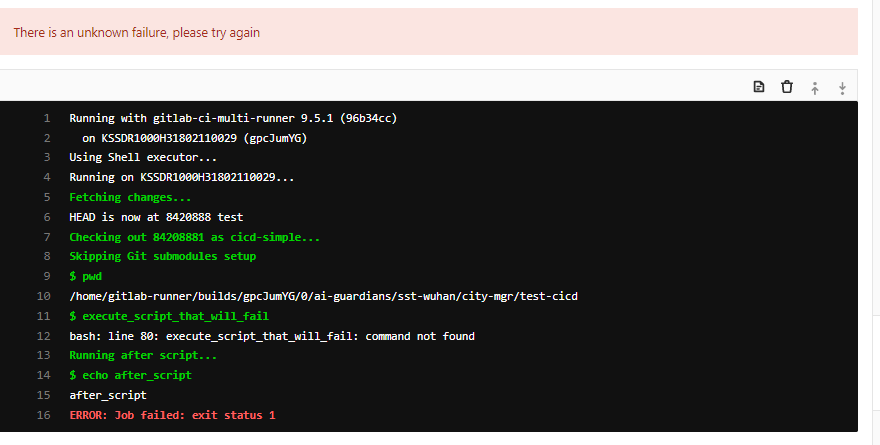
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 stages: - verify - build - dockerpush - deploy - cleanup before_script: - pwd after_script: - echo after_script unit-test: stage: verify tags: - test-cicd script: - echo unit-test java-package: stage: build tags: - test-cicd script: - echo build java-package2: stage: build tags: - test-cicd script: - execute_script_that_will_fail allow_failure: true docker-push: stage: dockerpush tags: - test-cicd script: - echo docker-push service-1: stage: deploy tags: - test-cicd script: - echo deploy when: manual cleanup_job: stage: cleanup tags: - test-cicd script: - echo clean up when: always
java-package2会执行错误
运行的pipeline如下,可见java-package2的执行错误
variables GitLab CI允许你为.gitlab-ci.yml增加变量,该变量将会被设置入任务环境。通过两种方式可以引用
示例如下:
1 2 3 4 5 6 7 8 9 10 variables: SOFT_VERSION: '1.0' TAG_NAME: 'xxx' docker-build: stage: dockerpush tags: - test-cicd script: - docker build -t $TAG_NAME:${SOFT_VERSION}
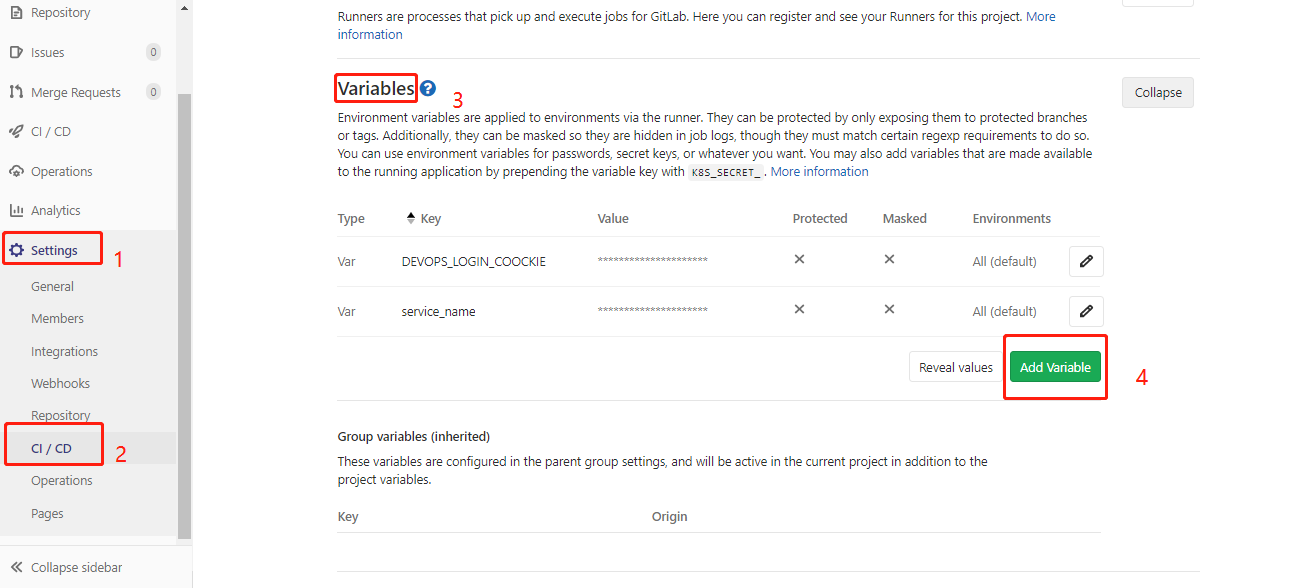
如果有些值不想在配置文件中显示,比如密码什么的,可以在代码仓库中setting->CICD->Variables 自定义变量,跟在.gitlab-ci.yml配置变量效果是一样的
variables的保留字 gitlab-ci有一些预定义变量,这些变量大部分以CI开头
预定义变量:
Variable
GitLab
Runner
Description
CI
all
0.4
标识该job是在CI环境中执行
CI_COMMIT_REF_NAME
9.0
all
用于构建项目的分支或tag名称
CI_COMMIT_REF_SLUG
9.0
all
先将$CI_COMMIT_REF_NAME的值转换成小写,最大不能超过63个字节,然后把除了0-9和a-z的其他字符转换成-。在URLs和域名名称中使用。
CI_COMMIT_SHA
9.0
all
commit的版本号
CI_COMMIT_TAG
9.0
0.5
commit的tag名称。只有创建了tags才会出现。
CI_DEBUG_TRACE
9.0
1.7
debug tracing 开启时才生效
CI_ENVIRONMENT_NAME
8.15
all
job的环境名称
CI_ENVIRONMENT_SLUG
8.15
all
环境名称的简化版本,适用于DNS,URLs,Kubernetes labels等
CI_JOB_ID
9.0
all
GItLab CI内部调用job的一个唯一ID
CI_JOB_MANUAL
8.12
all
表示job启用的标识
CI_JOB_NAME
9.0
0.5
.gitlab-ci.yml中定义的job的名称
CI_JOB_STAGE
9.0
0.5
.gitlab-ci.yml中定义的stage的名称
CI_JOB_TOKEN
9.0
1.2
用于同GitLab容器仓库验证的token
CI_REPOSITORY_URL
9.0
all
git仓库地址,用于克隆
CI_RUNNER_DESCRIPTION
8.10
0.5
GitLab中存储的Runner描述
CI_RUNNER_ID
8.10
0.5
Runner所使用的唯一ID
CI_RUNNER_TAGS
8.10
0.5
Runner定义的tags
CI_PIPELINE_ID
8.10
0.5
GitLab CI 在内部使用的当前pipeline的唯一ID
CI_PIPELINE_TRIGGERED
all
all
用于指示该job被触发的标识
CI_PROJECT_DIR
all
all
仓库克隆的完整地址和job允许的完整地址
CI_PROJECT_ID
all
all
GitLab CI在内部使用的当前项目的唯一ID
CI_PROJECT_NAME
8.10
0.5
当前正在构建的项目名称(事实上是项目文件夹名称)
CI_PROJECT_NAMESPACE
8.10
0.5
当前正在构建的项目命名空间(用户名或者是组名称)
CI_PROJECT_PATH
8.10
0.5
命名空间加项目名称
CI_PROJECT_PATH_SLUG
9.3
all
$CI_PROJECT_PATH小写字母、除了0-9和a-z的其他字母都替换成-。用于地址和域名名称。
CI_PROJECT_URL
8.10
0.5
项目的访问地址(http形式)
CI_REGISTRY
8.10
0.5
如果启用了Container Registry,则返回GitLab的Container Registry的地址
CI_REGISTRY_IMAGE
8.10
0.5
如果为项目启用了Container Registry,它将返回与特定项目相关联的注册表的地址
CI_REGISTRY_PASSWORD
9.0
all
用于push containers到GitLab的Container Registry的密码
CI_REGISTRY_USER
9.0
all
用于push containers到GItLab的Container Registry的用户名
CI_SERVER
all
all
标记该job是在CI环境中执行
CI_SERVER_NAME
all
all
用于协调job的CI服务器名称
CI_SERVER_REVISION
all
all
用于调度job的GitLab修订版
CI_SERVER_VERSION
all
all
用于调度job的GItLab版本
ARTIFACT_DOWNLOAD_ATTEMPTS
8.15
1.9
尝试运行下载artifacts的job的次数
GET_SOURCES_ATTEMPTS
8.15
1.9
尝试运行获取源的job次数
GITLAB_CI
all
all
用于指示该job是在GItLab CI环境中运行
GITLAB_USER_ID
8.12
all
开启该job的用户ID
GITLAB_USER_EMAIL
8.12
all
开启该job的用户邮箱
RESTORE_CACHE_ATTEMPTS
8.15
1.9
尝试运行存储缓存的job的次数
更多配置,可以参考官方参考文档:https://docs.gitlab.com/ee/ci/yaml/
更多精彩内容:mrxccc